
引言
前面已对java.util.HashMap的源码做了详细的分析。HashMap底层采用哈希表,保证了put和get操作的高效。但也导致了遍历操作是无序的。java.util.LinkedHashMap则是在HashMap的基础上,维护了一条双向链表,记录了节点的插入顺序。使遍历操作可以按插入顺序进行。本文通过源码解析的方式,对LinkedHashMap的有序性进行说明。
数据结构
LinkedHashMap继承自HashMap,在保持数组+链表+红黑树的结构下,还维护着一条双向链表,可以记录节点插入顺序。
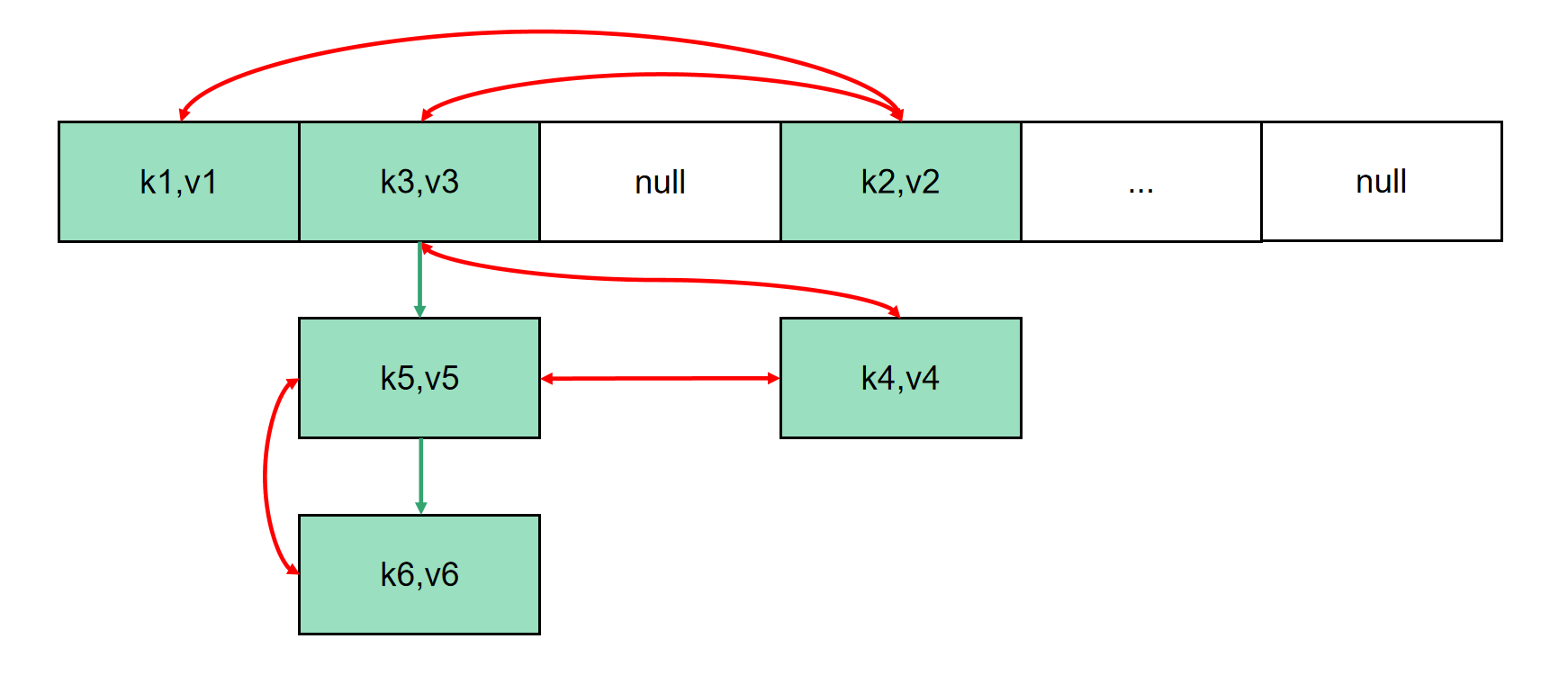
LinkedHashMap数据结构的最小单元是java.util.LinkedHashMap.Entry,LinkedHashMap.Entry在HashMap.Node的基础上,增加了指向前后节点的引用before和after。LinkedHashMap.Entry源码如下:
1 | static class Entry<K,V> extends HashMap.Node<K,V> { |
成员变量
指向双向链表头节点
1 | transient LinkedHashMap.Entry<K,V> head; |
指向双向链表尾节点
1 | transient LinkedHashMap.Entry<K,V> tail; |
是否改变访问顺序。开启这个,每次更新或查询节点都会将该节点移至双向链表末尾
1 | final boolean accessOrder; |
构造方法
所有LinkedHashMap构造方法内部都显示调用了父类HashMap构造方法。
构造一
默认accessOrder=false
1 | public LinkedHashMap() { |
构造二
指定数组初始容量,默认accessOrder=false
1 | public LinkedHashMap(int initialCapacity) { |
构造三
指定数组初始容量和加载参数,默认accessOrder=false
1 | public LinkedHashMap(int initialCapacity, float loadFactor) { |
构造四
指定数组初始容量、加载参数和accessOrder
1 | public LinkedHashMap(int initialCapacity, |
构造五
通过Map构建LinkedHashMap,默认accessOrder=false
1 | public LinkedHashMap(Map<? extends K, ? extends V> m) { |
成员方法
LinkedHashMap大部分还是沿用了HashMap的方法逻辑,通过对部分方法的改造,巧妙加入了链表的思想。
newNode方法
在HashMap#putVal方法中,通过newNode方法创建节点。
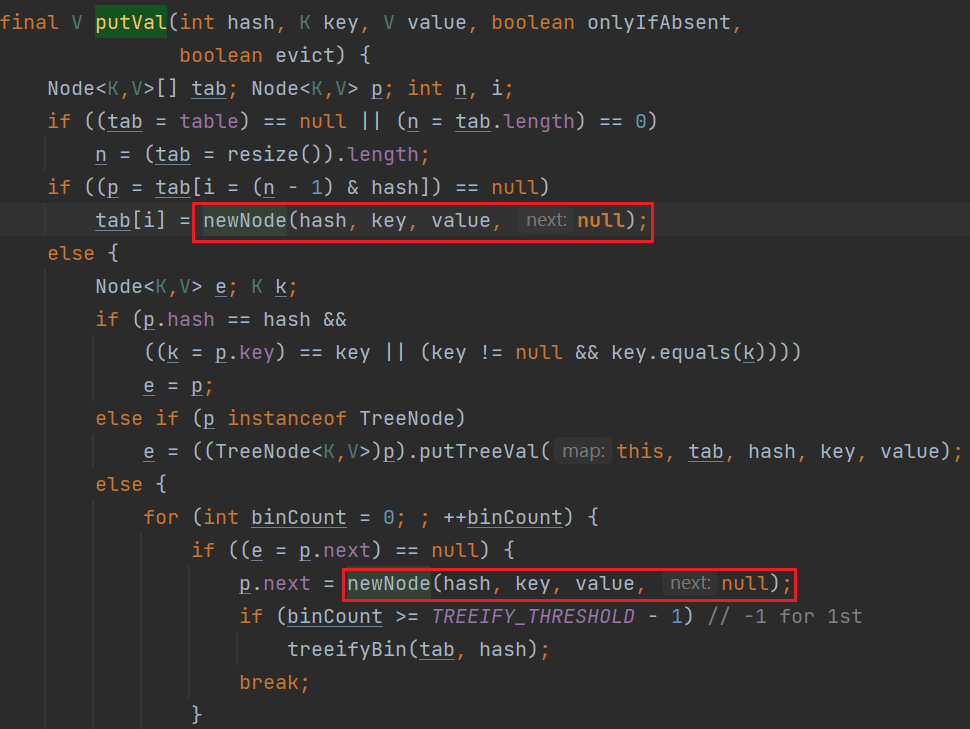
LinkedHashMap重写了newNode方法,使创建的节点类型为LinkedHashMap.Entry
1 | Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) { |
newNode内部调用了linkNodeLast方法。
linkNodeLast方法
给head,tail,before,after引用赋值,形成双向链表。通过这种方式,使添加的节点有了顺序
1 | private void linkNodeLast(LinkedHashMap.Entry<K,V> p) { |
afterNodeAccess方法
在putVal方法中,如果是更新value的情况,会调用一次afterNodeAccess方法。
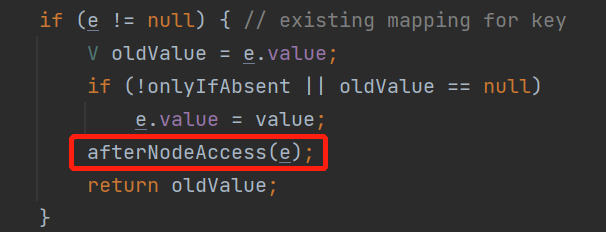
LinkedHashMap实现了afterNodeAccess方法,作用是:
每次更新节点后,都会将该节点移动到双向链表的末尾。
源码如下:
1 | void afterNodeAccess(Node<K,V> e) { |
注意:
accessOrder默认为false,需要手动开启。
总结起来,该方法处理了四种情况:
- e为尾节点,则不需要任何操作
- e为头节点,则b为null,需要将a设为头节点,e设为尾结点
- e为中间节点,则需要连接b和a,e设为尾结点
- 链表未初始化,则b,a都为null,e既是头节点也是尾结点
afterNodeInsertion方法
在putVal方法中,插入新的节点后,调用了afterNodeInsertion方法
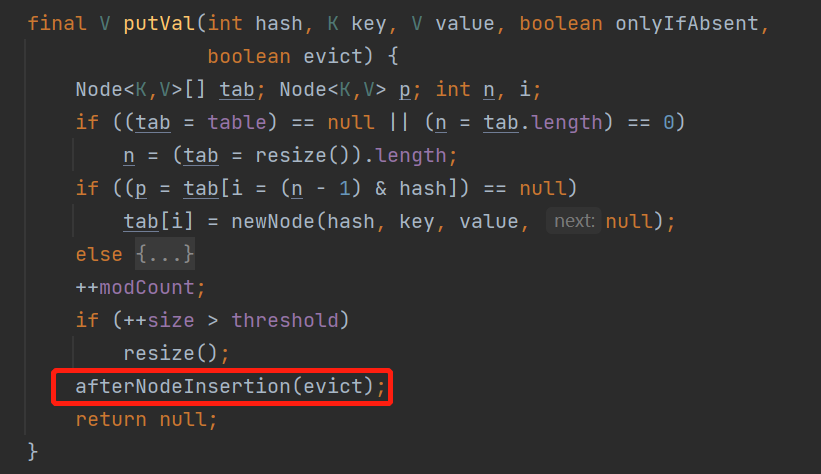
LinkedHashMap实现了该方法,作用是:
在插入新的节点后,移除双向链表的头节点。
源码如下:
1 | void afterNodeInsertion(boolean evict) { |
removeEldestEntry方法
注意removeEldestEntry方法默认返回false,需要重新实现。
1 | protected boolean removeEldestEntry(Map.Entry<K,V> eldest) { |
示例
重写removeEldestEntry方法,以满足:使map中节点数不超过3,超过自动移除
1 | public static void main(String[] args) { |
结果:
{1=1}
{1=1, 2=2}
{1=1, 2=2, 3=3}
{2=2, 3=3, 4=4}
{3=3, 4=4, 5=5}
再配合afterNodeAccess方法,将更新或查询的节点移动到链表末尾,就可以实现按使用频率淘汰旧数据的逻辑
afterNodeRemoval方法
在HashMap#removeNode方法中,删除节点后,会调用一次afterNodeRemoval方法。
LinkedHashMap实现了该方法,作用是:
在删除节点后,调整双向链表相关的引用。具体表现为:
-
首先移除e的前后引用
-
如果e是中间节点,则直接连接a、b节点
-
如果e是头节点,则使head指向a节点
-
如果e是尾节点,则使after指向b节点
1 | void afterNodeRemoval(Node<K,V> e) { |
get方法
get方法与 HashMap#get 方法基本相同,区别是如果accessOrder=true,会调用afterNodeAccess将该节点移动到双向链表末尾。
1 | public V get(Object key) { |
keySet方法
LinkedHashMap重写了keySet方法,使遍历按节点插入顺序进行。源码如下:
keySet方法返回LinkedHashMap.LinkedKeySet对象
1 | // 初次调用,会创建一个LinkedKeySet对象 |
LinkedKeySet类
iterator方法返回一个LinkedHashMap.LinkedKeyIterator迭代器对象
1 | final class LinkedKeySet extends AbstractSet<K> { |
LinkedKeyIterator类
next方法内部调用了LinkedHashMap.LinkedHashIterator#nextNode方法
1 | final class LinkedKeyIterator extends LinkedHashIterator implements Iterator<K> { |
LinkedHashIterator类
LinkedHashIterator初始化时会使next指向head节点,每调用一次nextNode方法,会使next在双向链表上移动一次。
可以看到,与HashMap.HashIterator#nextNode相比,LinkedHashMap.LinkedHashIterator#nextNode的指针是在双向链表上移动,既保留了数据插入的顺序,也提升了遍历效率。
1 | abstract class LinkedHashIterator { |
values和entrySet方法与keySet类似,这里不再展开


{kind=link}